Abstract
Research Overview
Methodology
Technical Approach
Our framework integrates three core components: Low-Rank Adaptation for efficient parameter tuning, Evolutionary Prompt Optimization for automatic prompt generation, and auxiliary processing techniques for error mitigation.
Low-Rank Adaptation (LoRA)
Efficient parameter tuning by updating only 0.3%-1.2% of model parameters through low-rank decomposition:
Applied to Query and Value projection layers in attention mechanisms, reducing parameters from dk to r(d+k).
Evolutionary Prompt Optimization
Genetic algorithm with population size 100, 50 iterations, using:
- Selection: Roulette sampling (top 30% retention)
- Crossover: Rate 0.8 with text segment splicing
- Mutation: Rate 0.2 with keyword replacement
- Fitness: WER on validation set
Auxiliary Error Mitigation
Multi-level error filtering mechanism:
- TokenLimit: Dynamic sequence truncation (45% WER contribution)
- Deduplication: Sliding window algorithm (30% redundancy reduction)
- Word Filtering: Domain-specific blacklist/whitelist
Results
Key Findings
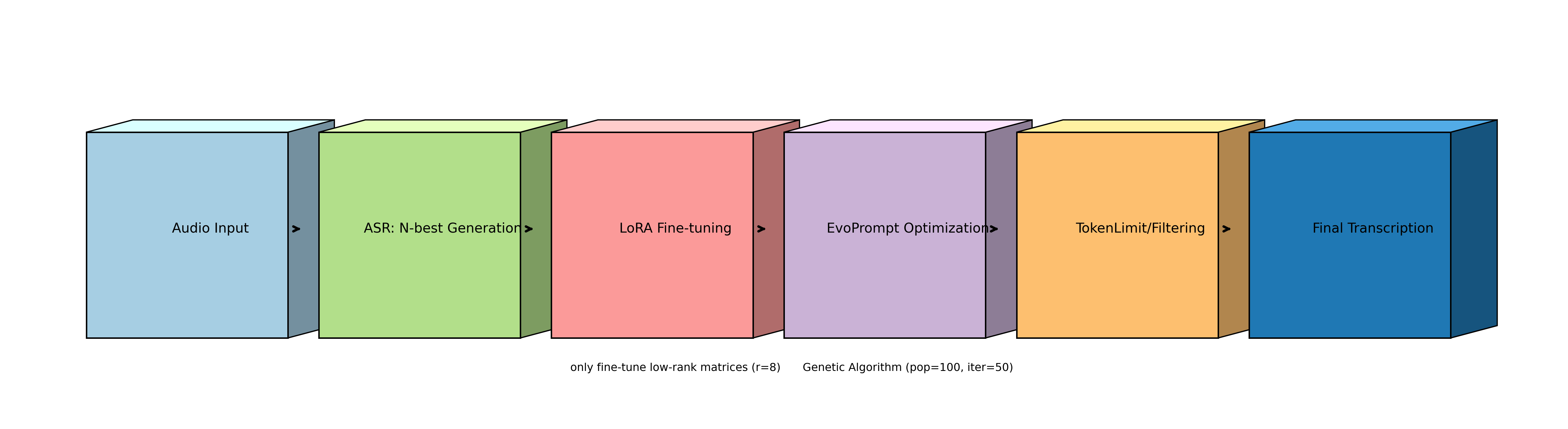
Figure 1: 3D visualization of evolutionary prompt optimization process showing initial population, selection, crossover, and mutation stages
Figure 2: Comprehensive WER comparison showing performance improvements across different models and configurations
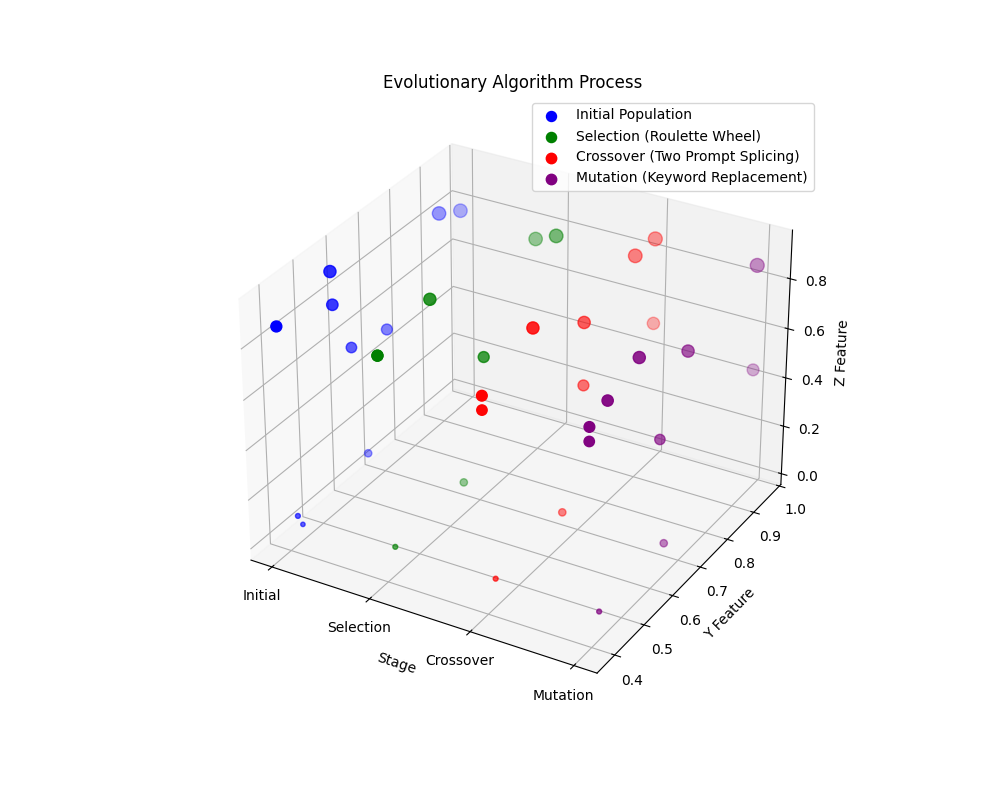
Figure 3: Radar chart showing the relative contribution of each technique component to overall WER reduction
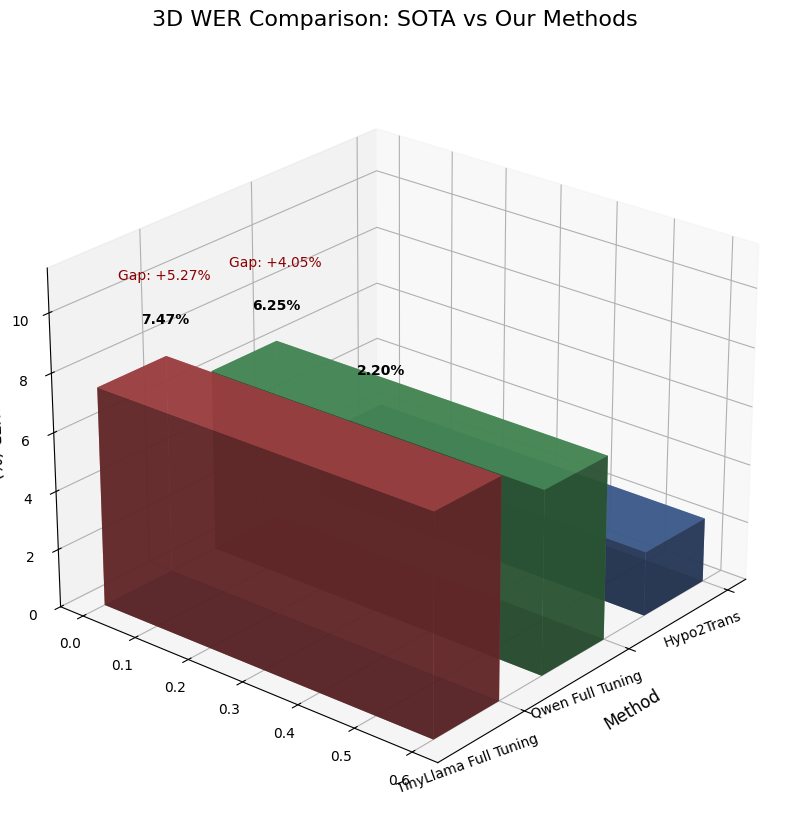
Figure 4: End-to-end process flow of the EvoLoRA framework from audio input to final transcription
Performance
Experimental Results
| Model | Parameters | Zero-shot WER | Optimized WER | Training Time | Parameter Updates |
|---|---|---|---|---|---|
| TinyLlama-1.1B | 1.1B | 285.89% | 7.47% | 2.3 GPU hours | 0.3% |
| Qwen2.5-7B | 7B | 1503.20% | 6.25% | 18.5 GPU hours | 1.2% (LoRA) |
| LLaMA-3.2-3B | 3.2B | 452.71% | 8.12% | 12.7 GPU hours | 100% |
| GPT-3.5 Turbo | 175B | 44.90% | 33.96% | 0.1 hours (API) | 0% |
Analysis
Ablation Study
Individual contribution of each component to overall WER reduction on Qwen2.5-7B
Discussion
Key Insights
Performance Bottlenecks and Limitations
Despite achieving significant performance improvements, our framework exhibits a 4.05% WER gap compared to SOTA method Hypo2Trans (2.20%). Core limitations include:
- Domain Adaptation: Limited coverage of specialized terminology and acoustic conditions
- Acoustic Information: Post-processing approach lacks explicit acoustic feature integration
- Sequence Modeling: Decreased efficiency with long N-best hypothesis sequences (>300 tokens)
Computational Efficiency Trade-offs
The framework achieves optimal balance between performance and resource consumption:
- Lightweight Model Advantage: TinyLlama-1.1B requires 87% less training time with only 1.22% WER increase
- LoRA Efficiency: 98.7% parameter reduction while maintaining 92% of full fine-tuning performance
- Scalability: Suitable for edge devices and resource-constrained scenarios
Research Contributions
This study proposes the EvoLoRA framework for resource-efficient ASR error correction, achieving significant performance improvements through synergistic integration of LoRA, EvoPrompt, and auxiliary techniques. Key contributions include:
- Methodological Innovation: Novel combination of low-rank adaptation and evolutionary prompt optimization
- Efficiency Achievement: 98.7% parameter reduction with minimal performance loss
- Practical Impact: Validation of "lightweight model + efficient optimization" paradigm for resource-constrained scenarios
The framework provides a cost-effective solution for ASR error correction in edge devices and low-resource environments, demonstrating that careful optimization can achieve competitive performance with significantly reduced computational requirements.